mvSQLite is the open-source, SQLite-compatible distributed database built on FoundationDB. Checkout my previous posts for some context:
In this post we benchmark mvSQLite with go-ycsb to see what its performance is like, and how a single database scales when we add more machines to the cluster.
Benchmark setup
We populate a table with 1 million rows, and then run all the YCSB workloads on the table for 200 seconds each.
Important go-ycsb parameters we set for the benchmark:
"threadcount"="64"
"sqlite.journalmode"="delete"
"sqlite.cache"="private"
"sqlite.maxopenconns"="1000"
"sqlite.maxidleconns"="1000"
"sqlite.optimistic"="true"
Additionally, we set the MVSQLITE_SECTOR_SIZE=16384 environment variable to configure mvSQLite to use 16K pages, set MVSQLITE_FORCE_HTTP2=1 to force HTTP2 usage, and listed all mvstore addresses in MVSQLITE_DATA_PLANE.
Baseline
Comparing with a baseline would help us understand the performance numbers. The baseline should be a SQLite-compatible distributed database that provides the same safety guarantees as mvSQLite: ACID-compliant, highly-available, and externally consistent.
Unfortunately, there are very few candidates that are as safe as mvSQLite. Asynchronous replication solutions like Litestream and LiteFS are ruled out (although they are great!), because durable HA fail-over is not possible and replica read violates external consistency. rqlite is the closest one - when the strong read consistency level is specified, it exhibits the same consistency and fault-tolerance properties as mvSQLite.
The minimal HA cluster
First, let’s run the benchmark with the smallest possible cluster. At least three nodes are required in any distributed system to maintain high-availability, so we’ll start three EC2 machines to run FoundationDB.
Cluster setup:
- FoundationDB: 3 x i4i.large, double replication, ssd-redwood-1-experimental storage engine, 2 processes per machine
- mvstore: 1 x c5.2xlarge, 3 processes
- ycsb: 1 x c6i.2xlarge
FoundationDB’s data is stored on the i4i instances’ local SSD. mvstore and ycsb machines are stateless and there is no data to store. The same i4i.large 3-node minimal cluster is started for rqlite, and data is persisted on the local SSD too.
Here are the numbers. The throughput is pretty nice:
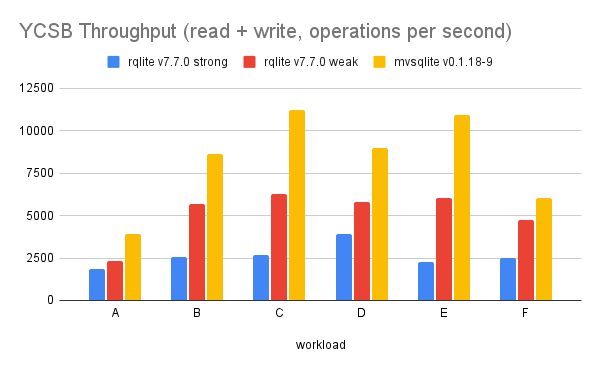
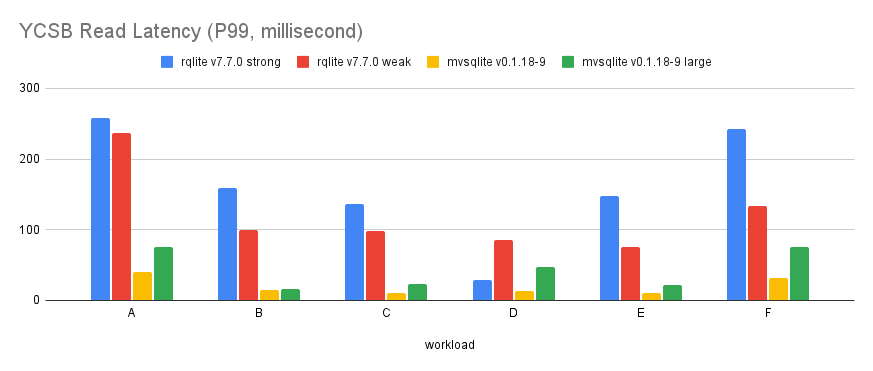
mvSQLite has a better tail read latency as well:
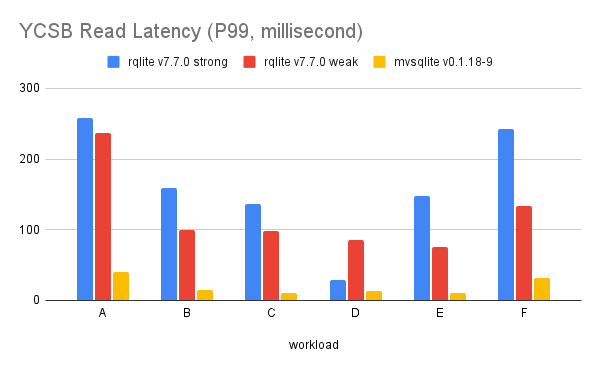
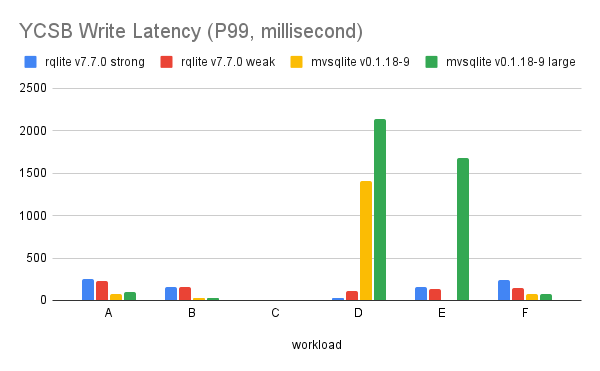
The write latency is more complicated though. Although mvSQLite is still better in most of the workloads, you can see the spike in YCSB workload D:
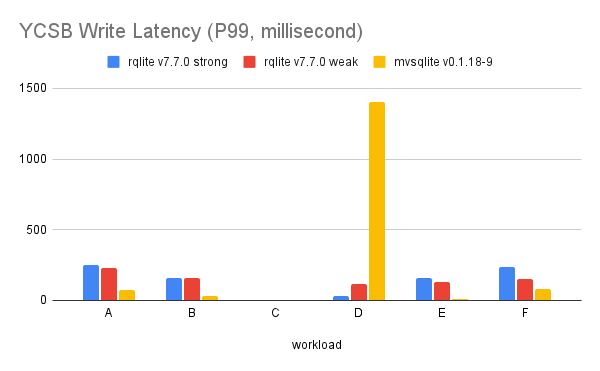
This is because workload D is an INSERT-heavy benchmark, and SQLite allocates rowids sequentially… meaning high contention here. Under an optimistic transaction model contention causes backoffs and retries, which add significant latency.
Add more machines!
I would like to know how mvSQLite actually scales. Although FoundationDB itself scales out linearly, mvSQLite adds a non-trivial layer on the top and the system may have other bottlenecks when scaling a single SQLite database.
Let’s double everything in the cluster. The new setup:
- FoundationDB: 6 x i4i.large, double replication, ssd-redwood-1-experimental storage engine, 2 processes per machine
- mvstore: 2 x c5.2xlarge, 5 processes
- ycsb: 1 x c6i.4xlarge, 2 processes
And the numbers are here. Throughput does increase for all workloads. but not all workloads get the same amount of performance improvement. The reasons are mainly transaction conflicts and read bandwidth bottleneck under double replication mode.
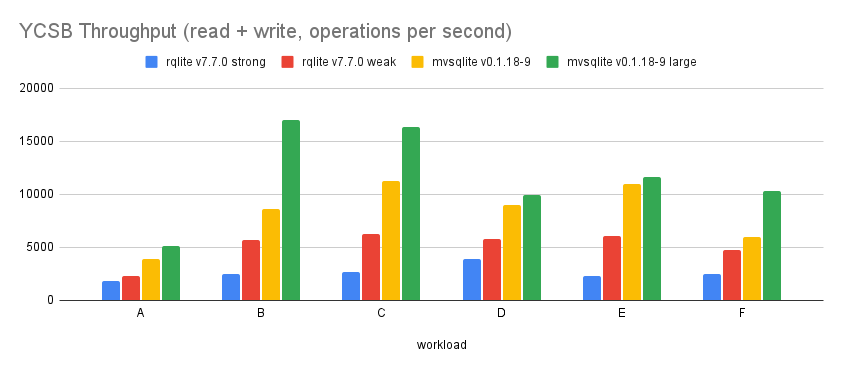
Tail read latency numbers. Indicator that some queue is being filled up in the system, but I haven’t traced it down:
Tail write latency numbers. One more spike.
Summary
I don’t really want to compare mvSQLite with rqlite, since they target different use cases (rqlite is “a central store for some critical relational data”, while mvSQLite intends to be a multi-tenant “sea of sqlite databases”). While mvSQLite is faster, it depends on a non-trivial external distributed system, FoundationDB. rqlite instead is fully self-contained and easier to deploy.
Around mvSQLite itself, The numbers here seems to indicate that:
- mvSQLite scales out pretty well for low-contention workloads.
- Optimistic transactions involving high-contention data can have long tail latencies
Raw data
Raw benchmark data is available here.