Self-hosting is an attractive thing to do for control and privacy. But it is potentially dangerous at the same time, in terms of both security and safety.
On the security side, there isn’t a team monitoring security vulnerabilities 24x7 for your Internet-facing applications. And on the safety side, hardware fails, software has bugs, people make mistakes, and you need to set up the system so that it does not throw away your precious data if a few hard disks failed or a script/yourself accidentally runs rm -rf /.
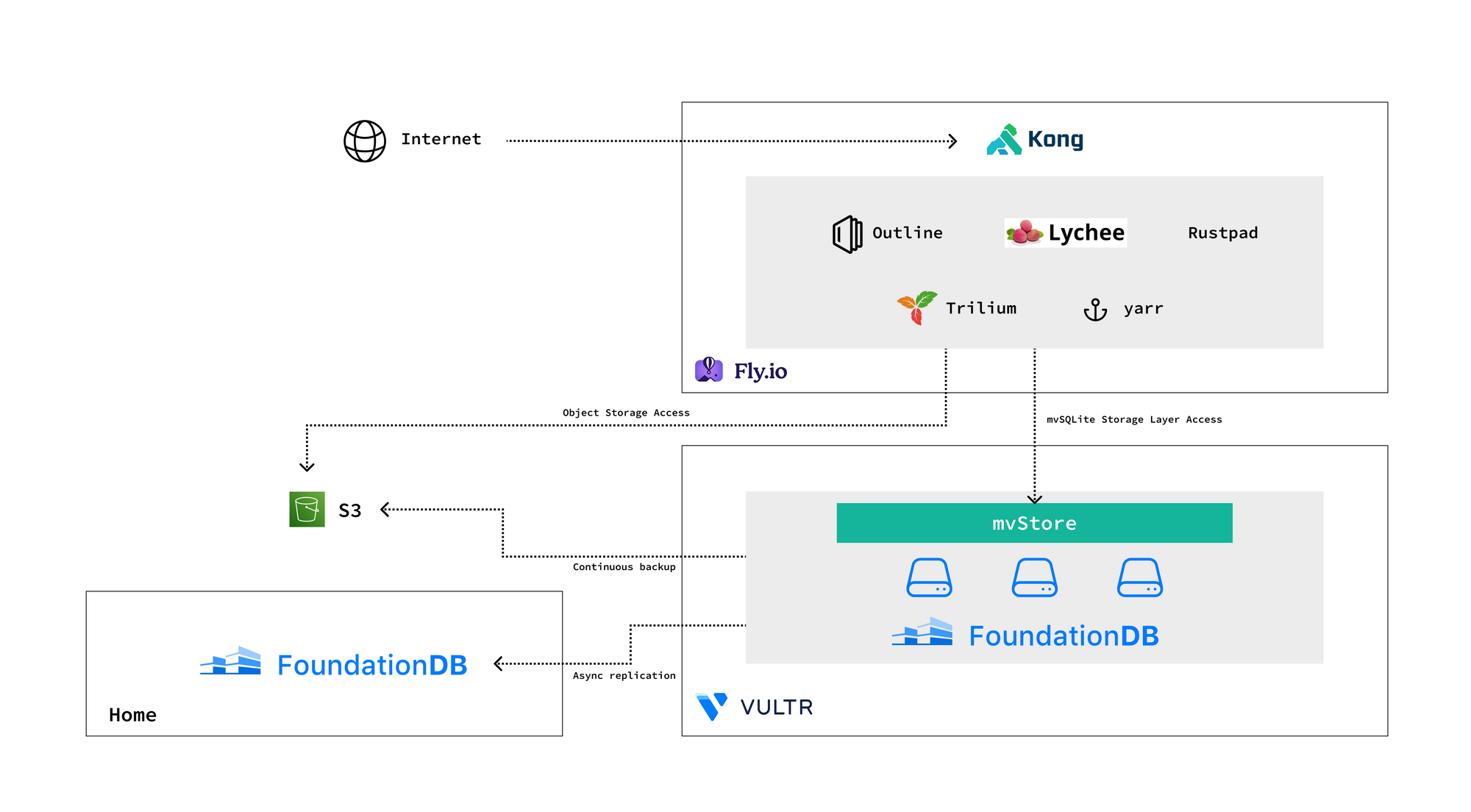
There needs to be a systematic solution to security and safety. The middle layers are fragile and this is just a fact arising from complexities; we should design the system around the fact, by having a solid foundation for data at the bottom and a solid ingress layer on the top accepting Internet traffic.
My setup
I run FoundationDB at the bottom, and Kong on the top. Inbound traffic goes through Kong. Most data is stored in FoundationDB, and large blobs are stored in S3.
All kinds of apps are deployed in the middle: Trilium (note-taking), yarr (RSS reader), Outline (Wiki), Lychee (photo management), Rustpad (collaborative editor), and a few that I developed myself.
Between the apps and FoundationDB is mvSQLite, the SQL layer. It seems that SQLite is kind of a greatest common divisor across most self-hosted apps, so we are getting pretty good compatibility. For those apps that don’t support SQLite though, I have to patch them.
On the operations side, I operate the FoundationDB clusters myself, and let Fly.io manage stateless services. No Kubernetes to work with, finally :)
Real-time system status is published on a public dashboard.
Data safety
As mentioned at the beginning of this post, safety is a desired system property. Any single service provider going down, one or two disk failures, or running rm -rf / once should not cause data loss. Let’s check this property against the setup.
The primary FoundationDB region is a 3-node, double-replication cluster that tolerates one machine failure. This cluster also runs on replicated block storage provided by the hosting provider, so we are pretty safe here.
On human and software errors, the first guard is mvSQLite’s multi-version feature. A bad DELETE SQL statement can be reverted - so an app won’t even be able to irreversibly delete its own data.
What if the FoundationDB cluster is accidentally teared down, a bug in mvSQLite caused corruption in its own data structure, or the hosting provider on which our cluster is hosted went down? We still have continuous backup - a FoundationDB mechanism that continuously ships mutation logs to external cold storage like S3. We can recover from the backup, with only a few seconds of data loss.
What if the backup on S3 is inaccessible too? I have another asynchronous FoundationDB replica at home with periodic ZFS snapshots, and data can be pulled out from it if needed.
Security
Another desired property is security. Random people on the Internet should not be able to access the private parts of my apps. A defense-in-depth approach is used here.
The first layer of defense is Kong. Private resources are protected by a JWT in a wildcard cookie. There is a dedicated service for authenticating and signing the JWT. Kong verifies the JWT cookie for each request.
The second layer of defense is each app’s own authentication and authorization. While this may not be as solid as the common JWT layer, it provides fine-grained access control for the clients that passed the first layer.
Summary
I’ve tried to do self-hosting and actually use the self-hosted system for a few times in the past years. Each time I gave up quickly because of the need to operate multiple distributed systems (Kubernetes, MySQL/PostgreSQL with replication, etc.) and the uncertainty around security and safety. The good thing is that technology advancements in the recent one or two years have greatly simplified a lot of things: there are now services like Fly.io that run and manage your containers properly, API gateways like Kong are easier to use, and rock-solid distributed databases like FoundationDB are getting better and better. So far I’m happy about my current setup.